
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- kafka #streamdata-processing #kafka-consumer
- Apache Druid #Apache Kafka #Apache Pinot #Real streaming
- Kibana
- kafka #streamdata-processing #mirrormaker
- kafka #mirrormaker consumer lag
- Today
- Total
더비창고방
Apache Druid deep storage 를 AWS s3로 사용해보기 본문
공식 doc link : https://druid.apache.org/docs/0.20.0/development/extensions-core/s3.html
참고 블로그 link : https://til.songyunseop.com/druid/setting_druid_with_emr.html
EMR과 함께 Druid를 셋팅해보자! — 전지적 송윤섭시점 TIL 1.0 documentation
Docs » EMR과 함께 Druid를 셋팅해보자! Edit on GitHub EMR과 함께 Druid를 셋팅해보자! Versions Druid 0.12.0 Java 1.8.0_161 과정 Java 설치 sudo yum install -y java-1.8.0-openjdk-devel.x86_64 druid User 추가 & druid 다운로드 & unzi
til.songyunseop.com
What is Deep storage ?

Deep storage 란, Segment (Druid의 데이터 저장 단위) 가 저장되는 곳으로 External storage와 같은 개념으로 생각하면 된다. Deep storage에 데이터를 저장함으로써 높은 데이터 내구성을 제공한다. (Druid의 노드를 잃어도 데이터는 잃지 않는다는 말로…?? )
Deep storage 는 아래 타입과 호환이 가능하다.
- Local
- Amazon S3
- 구글 클라우드 저장소
- Azure Blob 스토리지
- HDFS
Confiure S3 extension
S3 extension 을 사용하면 두가지 작업을 수행할 수 있다.
- Ingest data from files stored in S3 ( S3에 저장된 파일을 Druid에서 읽기 )
- Write segments to deep storage in S3 ( Druid 세그먼트를 S3에 저장 )
S3 extension을 사용하기 위해서는 common.runtime.properties 에 아래와같이 druid-s3-extenstions를 포함한다.
druid.extensions.loadList=["druid-hdfs-storage", "druid-kafka-indexing-service",
"druid-datasketches", "druid-basic-security", "druid-s3-extensions"]
Configure S3 as deep storage
[참고] Druid가 EC2 서버에서 실행되고있는 경우, 해당 EC2에 attached IAM role에 특정 bucket에 아래와같이 PutObject policy를 추가해서 사용해도 된다.
{
"Statement": [{
"Sid": "Access-to-specific-bucket-only",
"Principal": "*",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::DOC-EXAMPLE-BUCKET",
"arn:aws:s3:::DOC-EXAMPLE-BUCKET/*
]
}]
}
S3를 Deep storage로 사용하기 위해 common.runtime.properties 를 아래와 같이 설정한다.
# Deep storage
# For S3:
druid.storage.type=s3
druid.storage.bucket=your-bucket
druid.storage.baseKey=druid/segments
#druid.s3.accessKey=...
#druid.s3.secretKey=...
S3에 Druid Indexer log를 저장하려면 common.runtime.properties 를 아래와 같이 설정한다.
# Indexing service logs
# For S3:
druid.storage.type=s3
druid.storage.bucket=your-bucket
druid.storage.baseKey=druid/indexing-logs
** User credential 인증말고, ec2 IAM role로 할 수 있는 방법 ?????
관련 doc : https://druid.apache.org/docs/latest/development/extensions-core/s3.html
IAM ROLE policy의 Resource 위에처럼 주면 User credential 없이 indexing log는 s3에 적재되지만, segment는 s3에 적재되지 않아서 ㅜㅜ User credential을 명시하고 Druid 로그에서 accessKey와 secretKey 를 마스킹 하도록common.runtime.propeties 내에 아래와 같이 설정해두었다. 방법을 찾으면 수정해보려고 한다.
druid.startup.logging.maskProperties=["password", "secretKey", "awsSecretAccessKey"]
실행결과
kafka topic 데이터를 가져와 deep storage로 s3를 사용하는지 확인해본다.
참고 doc : https://druid.apache.org/docs/latest/tutorials/tutorial-kafka.html
stream load data를 하면, 아래와 같이 Supervisor와 Task 가 만들어진다.
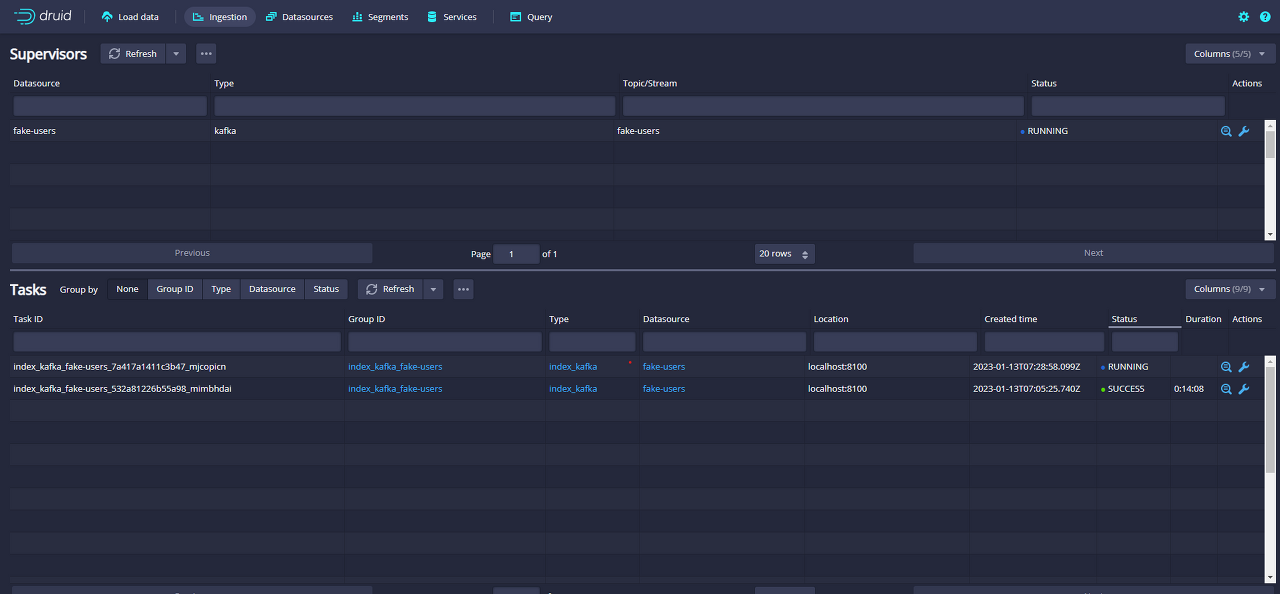
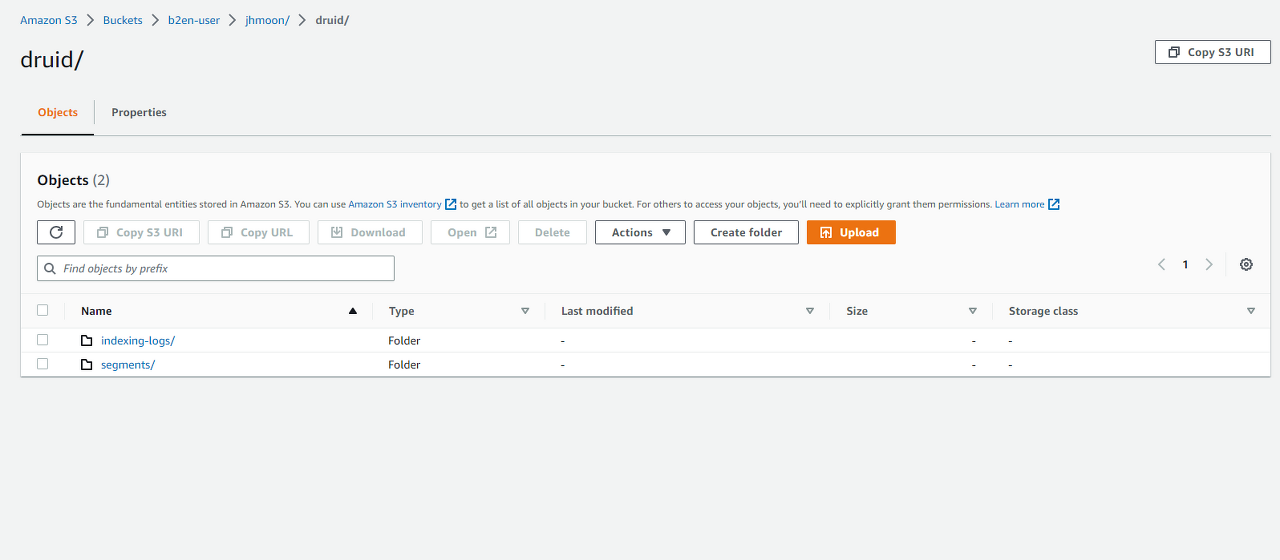
여기서, Superviser를 terminate를 하면 아래와 같이 properties 파일에 명시한 경로에 index log와 segments 가 저장된다.
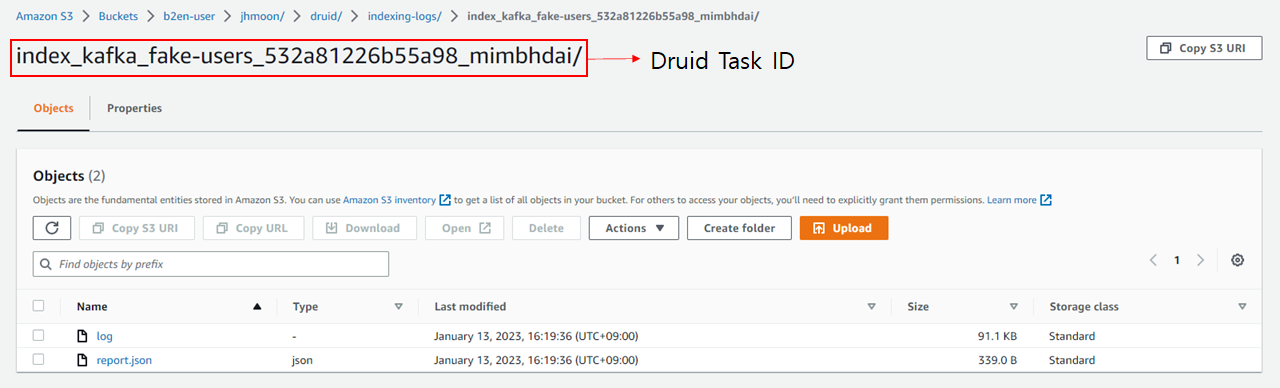
indexing log는 task id 를 prefix로 지정하여 생성이 된다.
segment는 segment가 생성된 시간기준으로 prefix를 생성하며, stream load data 생성시 설정한 partition 기준으로 deep storage에 segment를 저장한다.
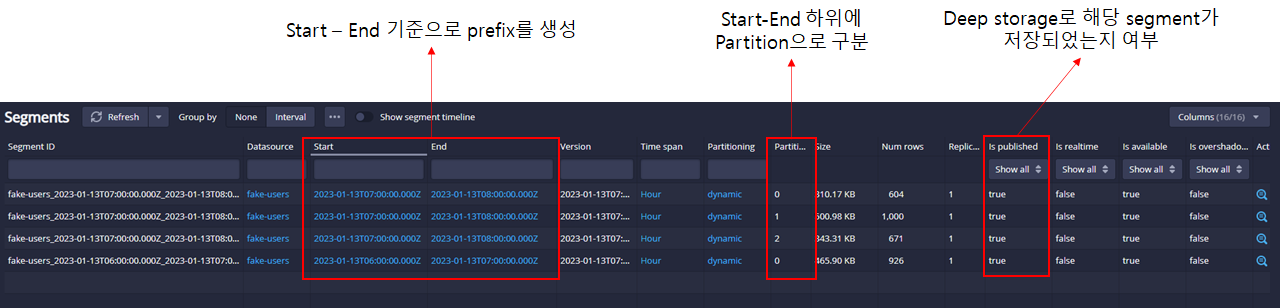
S3에 segment의 생성 Start time - End time 으로 prefix를 주며
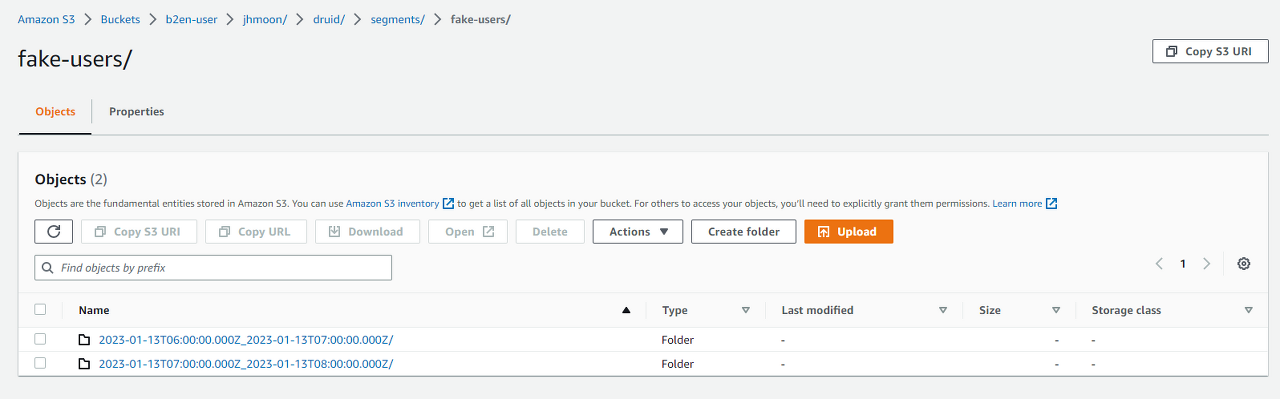
stream load data 생성시 설정한 partition 기준으로 segment가 s3에 적재된다.

'STUDY' 카테고리의 다른 글
| Apache Druid 를 활용한 실시간 데이터 처리 파이프 라인 구축 실습 (0) | 2023.01.18 |
|---|---|
| elasticsearch-kibana 사용자 인증 및 관리 (0) | 2022.12.20 |
| Kibana 설치하기 (1) | 2022.12.20 |
| MirrorMaker consumer lag 모니터링 (0) | 2022.12.20 |
| MirrorMaker 연동/기동 방법 (0) | 2022.12.20 |



