
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- kafka #streamdata-processing #kafka-consumer
- kafka #streamdata-processing #mirrormaker
- Kibana
- Apache Druid #Apache Kafka #Apache Pinot #Real streaming
- kafka #mirrormaker consumer lag
- Today
- Total
더비창고방
Apache Druid 를 활용한 실시간 데이터 처리 파이프 라인 구축 실습 본문
Realtime data streaming with Apache Kafka, Apache Pinot, Apache Druid and Apache Superset
Index
medium.com
Druid 솔루션에대해 공부해보고자 실시간 데이터처리 파이프라인 아키텍처를 찾던중, 위글을 접하게 되었다.
참고해서 실습해본 과정을 기록하고자 한다.
Toy project Architecture
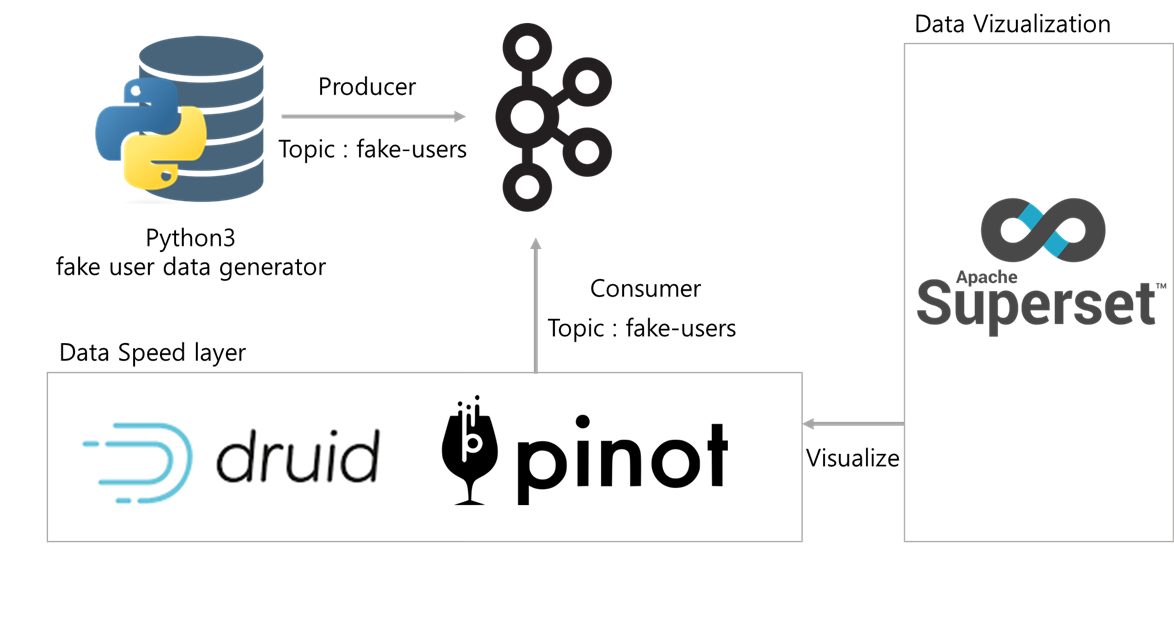
개요
- 플랫폼 : AWS ec2 서버
- 데이터 파이프라인 구성환경
- java version : openjdk version "1.8.0_342”
- Fake user data generator : python 3
- Zookeeper : docker로 설치, version : 3.7.0
- Kafka : ec2 서버 설치 , version : 2.7.1
- Druid : ec2 서버 설치, version : 0.22.0
- Pinot : docker로 설치, version : 0.7.1
- Superset : docker로 설치
1. docker-compose pinot container 생성
version: '3'
services:
zookeeper:
image: zookeeper:3.7.0
container_name: zookeeper
ports:
- "2181:2181"
- "2888:2888"
- "3888:3888"
- "8080:8080"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
pinot-controller:
image: apachepinot/pinot:0.7.1
command: "StartController -zkAddress zookeeper:2181"
container_name: pinot-controller
restart: unless-stopped
ports:
- "9000:9000"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms32M -Xmx100M -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log"
depends_on:
- zookeeper
pinot-broker:
image: apachepinot/pinot:0.7.1
command: "StartBroker -zkAddress zookeeper:2181"
restart: unless-stopped
container_name: "pinot-broker"
ports:
- "8099:8099"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms32M -Xmx100M -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-broker.log"
depends_on:
- pinot-controller
pinot-server:
image: apachepinot/pinot:0.7.1
command: "StartServer -zkAddress zookeeper:2181"
restart: unless-stopped
container_name: "pinot-server"
ports:
- "8098:8098"
environment:
JAVA_OPTS: "-Dplugins.dir=/opt/pinot/plugins -Xms32M -Xmx100M -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-server.log"
depends_on:
- pinot-broker
이후, {ec2 ip}:9000 으로 pinot 대시보드에 접속하여 확인한다.

2. kafka 설치와 설정
### kafka install
wget <https://archive.apache.org/dist/kafka/2.7.1/kafka_2.12-2.7.1.tgz>
tar -xvzf kafka_2.12-2.7.1.tgz
### kafka server configuration
export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m"
vi config/server.properties
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://{aws ec2 public ip}:9092
### kafka server start
./bin/kafka-server-start.sh -daemon config/server.properties
### Create topic
./bin/kafka-topics.sh --create --topic fake-users \\
--bootstrap-server localhost:9092 --partitions 3
#### Describe
./bin/kafka-topics.sh --describe --topic fake-users \\
--bootstrap-server localhost:9092
참고> 여기서 ec2 ip가 바뀌면서 zookeeper나 kafka 서버가 바뀌면서를 kafka 실행을 하면 아래와 같은 에러가 뜬다.

[2023-01-09 00:46:13,962] INFO [ExpirationReaper-0-Fetch]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper) ERROR Error while creating ephemeral at /brokers/ids/0, node already exists and owner '72057689747292160' does not match current session '72057604474798081' (kafka.zk.KafkaZkClient$CheckedEphemeral)
[2023-01-09 00:46:14,639] ERROR Error while creating ephemeral at /brokers/ids/0, node already exists and owner '72057689747292160' does not match current session '72057604474798081' (kafka.zk.KafkaZkClient$CheckedEphemeral) [2023-01-09 00:46:14,649] ERROR [KafkaServer id=0] Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer) org.apache.zookeeper.KeeperException$NodeExistsException: KeeperErrorCode = NodeExists at org.apache.zookeeper.KeeperException.create(KeeperException.java:126) at kafka.zk.KafkaZkClient$CheckedEphemeral.getAfterNodeExists(KafkaZkClient.scala:1837) at kafka.zk.KafkaZkClient$CheckedEphemeral.create(KafkaZkClient.scala:1775) at kafka.zk.KafkaZkClient.checkedEphemeralCreate(KafkaZkClient.scala:1742) at kafka.zk.KafkaZkClient.registerBroker(KafkaZkClient.scala:95) at kafka.server.KafkaServer.startup(KafkaServer.scala:312) at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:44) at kafka.Kafka$.main(Kafka.scala:82) at kafka.Kafka.main(Kafka.scala)
[원인] kafka server 시작시, server.properties 에 설정한 kafka-log 디렉토리 하위에 meta.properties를 찾아 열어보면, 아래와 같이 설정되어있다.
#Thu Jan 05 00:33:09 UTC 2023
cluster.id=S3_fGbIkS9CEL8ZFtYKskA
version=0
broker.id=0
정상적이지 않은 종료나, 재시작으로 broker.id에 해당하는 cluster.id 가 맞지 않아 생기는 에러이다.
이럴때는 server.properties에 설정한 kafka log의 디렉토리에서 meta.properties 를 제거하고 다시 실행한다.
3. Fake user data generator 실행한다. (python3로 실행)
fake_users_generator.py
import os
import random
import time
from time import sleep
import json
from faker import Faker
from kafka import KafkaProducer
from datetime import datetime
print("Iniciando a inserção de dados fakes...", end="\\n\\n")
print("Inicializando producer do kafka...")
topicName = "fake-users"
producer = KafkaProducer(bootstrap_servers=["localhost:9092"],
value_serializer=lambda x:
json.dumps(x).encode("utf-8"))
faker = Faker(["pt_BR"])
quantidade = 0
while 1==1 :
data = json.loads("{}")
data["id"] = random.getrandbits(32)
data["nome"] = faker.name()
data["sexo"] = random.choice("MF")
data["endereco"] = str((faker.address()).replace("\\n", " ").replace("\\r", "").strip())
data["cidade"] = str(faker.city())
data["cep"] = str(faker.postcode())
data["uf"] = str(faker.estado_sigla())
data["pais"] = str(faker.current_country())
data["telefone"] = faker.phone_number()
data["email"] = faker.safe_email()
data["foto"] = faker.image_url()
data["nascimento"] = str(faker.date_of_birth())
data["profissao"] = faker.job()
data["created_at"] = str(datetime.now())
data["updated_at"] = None
data["sourceTime"] = round(time.time() * 1000)
quantidade = quantidade + 1
print("[Registro: "+str(quantidade)+"]")
try:
print("---" * 20)
print("ID : " + str(data["id"]))
print("Nome : " + data["nome"])
print("Genero : " + data["sexo"])
print("Endereco : " + data["endereco"])
print("Cidade : " + data["cidade"])
print("Cep : " + data["cep"])
print("UF : " + data["uf"])
print("País : " + data["pais"])
print("Telefone : " + data["telefone"])
print("Email : " + data["email"])
print("Foto : " + data["foto"])
print("Nascimento : " + data["nascimento"])
print("Profissao : " + data["profissao"])
print("Criado em : " + data["created_at"])
print("Atualiz. Em : " + str(None))
print("sourceTime : " + str(data["sourceTime"]))
print("---" * 20, "\\n")
producer.send(topicName, value=data)
sleep(1)
except (Exception) as error:
print(error.message)
실행결과

kafka console consumer 로 topic에 데이터가 잘 유입되는지 확인한다.
./bin/kafka-console-consumer.sh \\
--bootstrap-server localhost:9092 \\
--topic fake-user
실행결과

4. Apache Druid 설치 및 설정
## Druid 설치
wget https://dlcdn.apache.org/druid/0.22.0/apache-druid-0.22.0-bin.tar.gz
tar -xvf apache-druid-0.22.0-bin.tar.gz
## Druid 설정
cd apache-druid-0.22.0/conf
sed -i 's/clientPort=2181/clientPort=12181/g' zk/zoo.cfg
echo "admin.serverPort=18080" >> zk/zoo.cfg
sed -i 's/druid.zk.service.host=localhost/druid.zk.service.host=localhost:12181/g' druid/single-server/nano-quickstart/_common/common.runtime.properties
sed -i 's/druid.plaintextPort=8081/druid.plaintextPort=18081/g' druid/single-server/nano-quickstart/coordinator-overlord/runtime.properties
sed -i 's/druid.plaintextPort=8091/druid.plaintextPort=18091/g' druid/single-server/nano-quickstart/middleManager/runtime.properties
sed -i 's/druid.plaintextPort=8082/druid.plaintextPort=18082/g' druid/single-server/nano-quickstart/broker/runtime.properties
sed -i 's/druid.plaintextPort=8083/druid.plaintextPort=18083/g' druid/single-server/nano-quickstart/historical/runtime.properties
sed -i 's/druid.plaintextPort=8888/druid.plaintextPort=18888/g' druid/single-server/nano-quickstart/router/runtime.properties
## Druid online with superset
echo '' >> apache_druid/apache-druid-0.22.0/conf/druid/single-server/nano-quickstart/_common/common.runtime.properties
sed -i 's/"druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches"/"druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches", "druid-basic-security"/g' /root/apache_druid/apache-druid-0.22.0/conf/druid/single-server/nano-quickstart/_common/common.runtime.properties
echo '
#
# Authentication
#
druid.auth.authenticatorChain=["MyBasicMetadataAuthenticator"]
druid.auth.authenticator.MyBasicMetadataAuthenticator.type=basic
druid.auth.authenticator.MyBasicMetadataAuthenticator.initialAdminPassword=superTestDruid
druid.auth.authenticator.MyBasicMetadataAuthenticator.initialInternalClientPassword=superTestDruid
druid.auth.authenticator.MyBasicMetadataAuthenticator.credentialsValidator.type=metadata
druid.auth.authenticator.MyBasicMetadataAuthenticator.skipOnFailure=false
druid.auth.authenticator.MyBasicMetadataAuthenticator.authorizerName=MyBasicMetadataAuthorizer
#Escalator
druid.escalator.type=basic
druid.escalator.internalClientUsername=admin
druid.escalator.internalClientPassword=superTestDruid
druid.escalator.authorizerName=MyBasicMetadataAuthorizer
#Authorizer
druid.auth.authorizers=["MyBasicMetadataAuthorizer"]
druid.auth.authorizer.MyBasicMetadataAuthorizer.type=basic' >> /root/apache_druid/apache-druid-0.22.0/conf/druid/single-server/nano-quickstart/_common/common.runtime.properties
sed -i 's/druid.host=localhost/druid.host='"$(hostname -i)"'/g' /root/apache_druid/apache-druid-0.22.0/conf/druid/single-server/nano-quickstart/_common/common.runtime.properties
Druid 실행
cd ..
export DRUID_SKIP_JAVA_CHECK=1
export DRUID_SKIP_PORT_CHECK=1
./bin/start-nano-quickstart
이후, {ec2 ip}:18888 으로 Druid 대시보드에 접속하여 확인한다.

5. Kafka -> Apache Druid 데이터 로드하기
아래 링크를 참고하여 진행
https://druid.apache.org/docs/latest/tutorials/tutorial-kafka.html
Tutorial: Load streaming data from Apache Kafka · Apache Druid
<!--
druid.apache.org
(1) Druid 상단 Load data 메뉴를 클릭하고, kafka 선택 후 connect data를 클릭한다.

(2) kafka bootstrap-server와 topic 정보를 입력하고, apply클릭 후 연결 확인이 되면 우측 하단 parse data를 클릭한다.

(3) input data의 포맷을 설정하고 parse time을 클릭한다.

(4) Druid에서는 기본적으로 사용할 타임스탬프 column 을 지정해야 한다. 타임스탬프로 지정할 column 이 없을 경우, Parse timestamp from 에서 None을 지정하고 Place holder 값을 넣을 수 있다.

(5) 변환 및 필터, 스키마구성과 파티션 설정을 완료하고 submit을 클릭한다.
** 변환 및 필터, 스키마구성과 파티션 설정에대한 설명은 따로 다룰 예정

이후, supervisor와 task가 생성되어 데이터수집을 하며 Query 메뉴에서 수집된 데이터 조회가 가능하다.

6. Kafka -> Apache Pinot 데이터 로드하기
pinot 내 스키마와 테이블 생성을 위해 pinot 콘솔화면에서 Swagger REST API 페이지에 들어간다.

Schema → POST/schemas 항목에서 아래 스키마 추가를 한다.
{
"schemaName": "realtime_users",
"metricFieldSpecs": [
{
"name": "id",
"dataType": "INT"
}
],
"dimensionFieldSpecs": [
{
"name": "nome",
"dataType": "STRING"
},
{
"name": "sexo",
"dataType": "STRING"
},
{
"name": "endereco",
"dataType": "STRING"
},
{
"name": "cidade",
"dataType": "STRING"
},
{
"name": "cep",
"dataType": "STRING"
},
{
"name": "uf",
"dataType": "STRING"
},
{
"name": "pais",
"dataType": "STRING"
},
{
"name": "telefone",
"dataType": "STRING"
},
{
"name": "email",
"dataType": "STRING"
},
{
"name": "foto",
"dataType": "STRING"
},
{
"name": "nascimento",
"dataType": "STRING"
},
{
"name": "profissao",
"dataType": "STRING"
},
{
"name": "created_at",
"dataType": "STRING"
},
{
"name": "updated_at",
"dataType": "STRING"
}
],
"dateTimeFieldSpecs": [
{
"name": "sourceTime",
"dataType": "LONG",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}
아래 명령어를 수행해도 된다.
curl -X POST "http://{ec2_public_ip}:9000/schemas?override=true"
-H "accept: application/json" -H "Content-Type: application/json"
-d "{ \\"schemaName\\": \\"realtime_users\\",
\\"metricFieldSpecs\\": [ { \\"name\\": \\"id\\", \\"dataType\\": \\"INT\\" } ],
\\"dimensionFieldSpecs\\": [ { \\"name\\": \\"nome\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"sexo\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"endereco\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"cidade\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"cep\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"uf\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"pais\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"telefone\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"email\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"foto\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"nascimento\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"profissao\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"created_at\\", \\"dataType\\": \\"STRING\\" },
{ \\"name\\": \\"updated_at\\", \\"dataType\\": \\"STRING\\" } ],
\\"dateTimeFieldSpecs\\": [ { \\"name\\": \\"sourceTime\\", \\"dataType\\": \\"LONG\\",
\\"format\\": \\"1:MILLISECONDS:EPOCH\\",
\\"granularity\\": \\"1:MILLISECONDS\\" } ]}"
Table → POST/tables 항목에서 아래 테이블을 생성한다.
{
"tableName": "realtime_users",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "sourceTime",
"timeType": "MILLISECONDS",
"schemaName": "realtime_users",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "fake-users",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "{ec2-public-ip}:9092",
"realtime.segment.flush.threshold.time": "3600000",
"realtime.segment.flush.threshold.size": "50000",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}
아래와같이 pinot 쿼리 콘솔에서 kafka fake-user 데이터를 볼 수 있다.

7. Pinot에 저장된 데이터 superset BI tool로 시각화하기
supertset docker 유저 생성
docker exec -it superset superset fab create-admin \\
--username admin \\
--firstname **** \\
--lastname **** \\
--email ****@****.com \\
--password superTest{ec2-public-ip}:13005 로 접속하면 아래와 같이 superset 화면이 나온다
userrname ; admin , password ; superTest 으로 로그인 한다.
pinot Database 연결을 한다.

상단 메뉴바에서 Data를 클릭하고 Database를 클릭한후 +DATABASE를 클릭한다.
pinot을 선택하고, SQLALCHEMY URI 란에 아래 주소를 입력한다.
pinot://{ec2-public-ip}:8099/query/sql?
controller=http://{ec2-public-ip}:9000
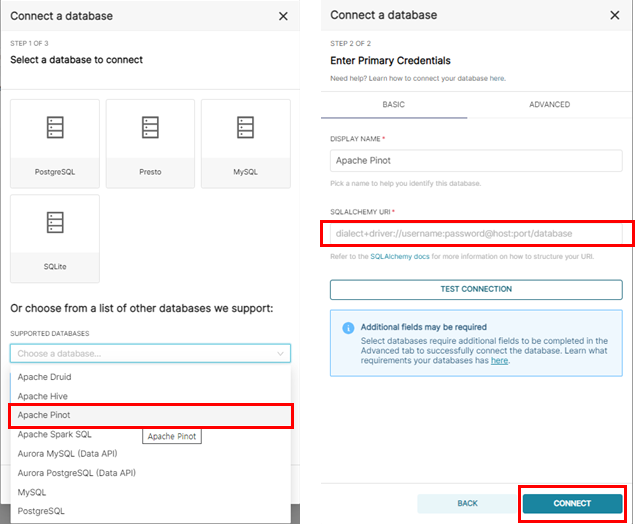
Dataset을 연결한다.


SQL lab에서 아래와같이 쿼리로 데이터 조회가 가능하다.

아래와같이 super set 차트생성도 가능하다
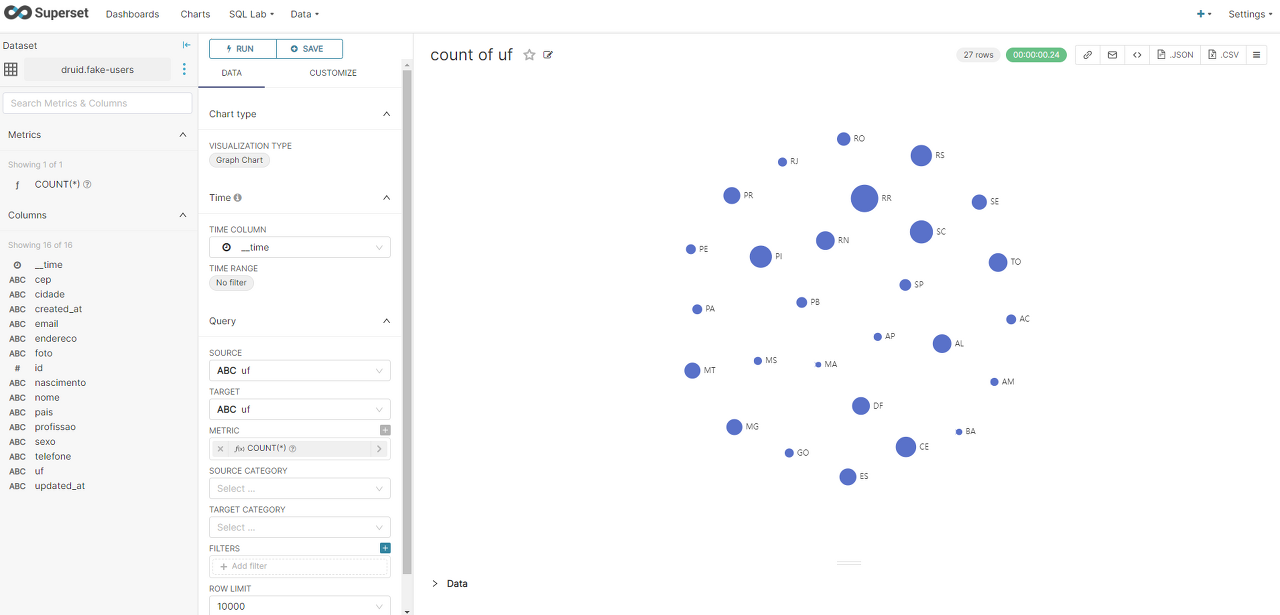
덧. >> 전체 프로세스를 on/off 하는 쉘
start.sh
#!/usr/bin/env bash
getNow()
{
echo "`date '+%Y-%m-%d %H:%M:%S'`"
}
getNowTimestamp()
{
echo "`date '+%s'`"
}
# SET VARIABLE
EXEC_DT="`date '+%Y%m%d_%H%M%S'`"
RUN_FILE=$0
RUN_FILE_REALPATH=`realpath ${RUN_FILE}`
RUN_FILE_NAME=`basename ${RUN_FILE_REALPATH}`
RUN_FILE_DIR=`dirname ${RUN_FILE_REALPATH}`
RUNNER=`whoami`
ZK_LOG_FILE="/home/ec2-user/log/zookeeper/zookeeper.log"
PN1_LOG_FILE="/home/ec2-user/log/pinot/pinot-controller.log"
PN2_LOG_FILE="/home/ec2-user/log/pinot/pinot-broker.log"
PN3_LOG_FILE="/home/ec2-user/log/pinot/pinot-server.log"
SP_LOG_FILE="/home/ec2-user/log/superset/superset.log"
KFK_LOG_FILE="/home/ec2-user/log/kafka/kafka.log"
DRD_LOG_FILE="/home/ec2-user/log/druid/druid.log"
# env on program start
echo -e "[$(getNow)] ${RUN_FILE_NAME} Start. \n"
# docker start
sudo systemctl start docker
echo -e "[$(getNow)] docker Start. \n"
# zookeeper start
docker start zookeeper
sudo docker logs zookeeper > ${ZK_LOG_FILE} 2>&1
echo -e "[$(getNow)] zookeeper Start. log diretory is ${ZK_LOG_FILE} \n"
# pinot-controller start
docker start pinot-controller
sudo docker logs pinot-controller > ${PN1_LOG_FILE} 2>&1
echo -e "[$(getNow)] pinot-controller Start. log diretory is ${PN1_LOG_FILE} \n"
# pinot-broker start
docker start pinot-broker
sudo docker logs pinot-broker > ${PN2_LOG_FILE} 2>&1
echo -e "[$(getNow)] pinot-broker Start. log diretory is ${PN2_LOG_FILE} \n"
# pinot-server start
docker start pinot-server
sudo docker logs pinot-server > ${PN3_LOG_FILE} 2>&1
echo -e "[$(getNow)] pinot-server Start. log diretory is ${PN3_LOG_FILE} \n"
# superset start
docker start superset
sudo docker logs superset > ${SP_LOG_FILE} 2>&1
echo -e "[$(getNow)] superset Start. log diretory is ${SP_LOG_FILE} \n"
# get my PUBLIC_IP
MY_PUBLIC_IP=$(curl -s ifconfig.me)
# change kafka bootstrap-server address
sed -i "/advertised.listeners/ c\advertised.listeners=PLAINTEXT://${MY_PUBLIC_IP}:9092" ~/kafka_2.12-2.7.1/config/server.properties
echo -e "[$(getNow)] change kafka bootstrap-server address ${MY_PUBLIC_IP}:9092\n"
# kafka start
# 1. kafka meta.properties remove
rm /tmp/kafka-logs/meta.properties
# 2. kafka server start
/home/ec2-user/kafka_2.12-2.7.1/bin/kafka-server-start.sh /home/ec2-user/kafka_2.12-2.7.1/config/server.properties >> ${KFK_LOG_FILE} 2>&1 &
echo -e "[$(getNow)] kafka start. log directory is ${KFK_LOG_FILE} \n"
sleep 10
# druid start
export DRUID_SKIP_JAVA_CHECK=1
export DRUID_SKIP_PORT_CHECK=1
/home/ec2-user/apache-druid-0.22.0/bin/start-nano-quickstart >> ${DRD_LOG_FILE} 2>&1 &
echo -e "[$(getNow)] Druid start. log directory is ${KFK_LOG_FILE} \n"
sleep 10
# fake data generator start
source /home/ec2-user/my_app/env/bin/activate
sleep 10
nohup python3 /home/ec2-user/py_script/fake_user_generator.py &
echo -e "[$(getNow)] fake user data generator.py start \n"
# env on program end
echo -e "[$(getNow)] ${RUN_FILE_NAME} End. \n"
stop.sh
#!/usr/bin/env bash
getNow()
{
echo "`date '+%Y-%m-%d %H:%M:%S'`"
}
getNowTimestamp()
{
echo "`date '+%s'`"
}
# env off program start
echo -e "[$(getNow)] ${RUN_FILE_NAME} Start. \n"
# python generator stop
kill -9 `ps -ef |grep python |grep -v grep | awk '{print $2}'`
echo -e "[$(getNow)] python generator stop. \n"
# docker stop
echo -e "[$(getNow)] docker process stop. \n"
docker stop $(docker ps -qa)
# druid stop
/home/ec2-user/apache-druid-0.22.0/bin/service --down
echo -e "[$(getNow)] druid process stop. \n"
# kafka stop
kill -9 `ps -ef |grep Kafka |grep -v grep | awk '{print $2}'`
echo -e "[$(getNow)] kafka process stop. \n"
# env off program end
echo -e "[$(getNow)] ${RUN_FILE_NAME} end. \n"
'STUDY' 카테고리의 다른 글
| Apache Druid deep storage 를 AWS s3로 사용해보기 (1) | 2023.01.18 |
|---|---|
| elasticsearch-kibana 사용자 인증 및 관리 (0) | 2022.12.20 |
| Kibana 설치하기 (1) | 2022.12.20 |
| MirrorMaker consumer lag 모니터링 (0) | 2022.12.20 |
| MirrorMaker 연동/기동 방법 (0) | 2022.12.20 |



